Monet sparsity optimization
In Spring 2025, EleutherAI was working on replacing layers in pretrained transformers with sparse transcoders(1, 2). We could finetune transcoders to match or even improve on the models on crossentropy, but we needed to make the MLPs so wide that inference was impractical.
"Product Key Memory Sparse Coders" was one of our attempts to improve transcoder efficiency. The main bottleneck in transcoder inference is the encoder forward pass. We need to compute the outputs of a very wide MLP, usually an OOM wider than a usual MLP encoder. We considered various ways to decompose the weights to speed up the forward pass, but they rarely yielded a Pareto improvement. We have not considered ideas like quantized training, only focusing on the architecture.
One MLP architecture we considered was Monet. This architecture was used by the authors for from-scratch pretraining, and not replacing individual layers like in our experiments. Monet is closer to an MoE than a sparse coder. It has a very large (262k) number of small (~12 hidden dimension) experts, and the weights of each are compressed using one of two schemes (Section 3).
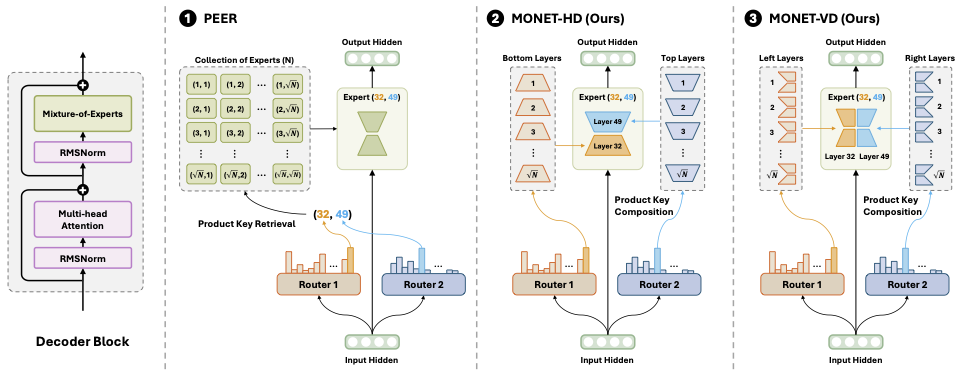
The basic idea behind them is to divmod the expert index by the square root of the index count and use the two indices to find pieces of the weights used for inference. This strategy is inspired by product key memories, but is not a direct port like our PKM sparse coders were. There is a router every 4 layers, and it is also decomposed with PKM, meaning. Monet achieves comparable accuracy to a dense model of the same size and has interpretable features1 by default.
An implementation of the Monet MLP can be found in the official Github repo. The core forward pass of a vertically decomposed Monet is as follows:
# x: b, t, d_in
# g1, g2: b, t, moe_heads, moe_experts
, = ,
=
=
# x1, x2: b, t, moe_experts, moe_dim // 2
# each represents half of the hidden dimension of the MLP
=
=
=
=
=
=
# x11, x12, x13, x21, x22, x23: b, t, d_in // 2
# x11/x22: result of a forward pass through a single chosen half-MLP
# x12/x21: results from passing a half-MLP’s post-activations into another half-MLP
# x13/x23: contributions from the biases of the chosen half-MLPs
return
Notice that this implementation doesn't make use of the sparsity of the picked experts. I benchmarked this implementation against other language models:
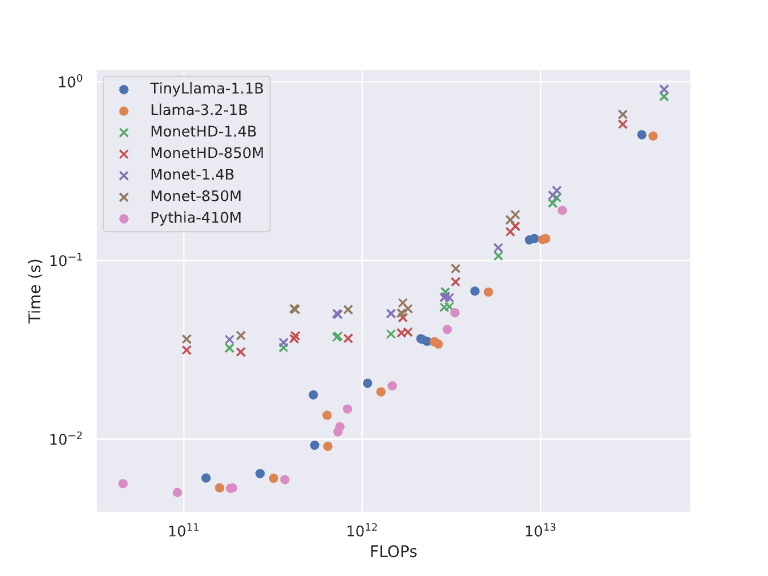
This shows that the model is implemented efficiently for the amount of FLOPs it uses when the batch size is high enough. Of course, these numbers count all sparse operations as dense ones and thus overestimate the number of operations a sparse implementation would need to perform. For all Monet sizes, a FLOP reduction of 30x or more is achievable for the MLP operations if sparsity is taken advantage of fully and the TopK operation is sped up.
All three of the Monet MLP operations can be rewritten to take advantage of the sparsity. I tried optimizing the bias and the same-half affine operations using the sparse matmul kernel (Gao et al. 2024, DenseSparseMatmul), and it did not improve MLP forward pass time at 1.4B. Another obstacle to using sparse kernels is that it also requires us to know the indices of the active elements, which requires an expensive TopK operation. The original Monet paper avoided it by approximating the TopK threshold using the Normal CDF and setting values below the threshold to 0 without selecting their indices. A change that would make any optimization viable in the first place is changing the from thresholded TopK to Maxout:
=
, =
= + *
return ,
We don’t know if this change preserves language modelling performance, but would expect it to, as Maxout works similarly to TopK for sparse coders. Testing this would require retraining the model.
With this change, the cross-half part of the forward pass can be slightly sped up by considering only the active indices in the tensor contraction:
=
=
=
=
=
=
=
return
Where g1_i/g1_v (and g2_i/g2_v) are the indices and values of the top K elements of g1 and g2 for each head (shape B x T x moe_heads x moe_experts).
This speeds up a forward pass on 2^16 tokens with Monet-VD-850M from 46ms to 35ms; with 1.4B from 62.3ms to 54.8ms; on 3*2^14 tokens with 4.1B from 90ms to 80ms. The speedup seems to stabilize at around 12% for large models.
These tests were run on 1 A40 GPU. We briefly tested if a CPU implementation could see an improvement, but found that there was no benefit over an AVX2 dense matrix multiplication on AMD EPYC 7B12 at the current levels of sparsity.
Thus Monet joins the list of architectures that have a clever sparsity trick but don't see performance improvements from it.
As measured by autointerp. We didn't publish these results.
Sparsity should speed up each component of the encoder by approximately moe_experts/moe_k:
= * * + * *
= * * + * *
= * * + * * + * *
= * * + * * + * *
= *
= *
= + +
= + +
This ratio is 64 for the 850M model (leading to ~57.273 estimated FLOPs ratio).